Join our Newsletter
Contact
webmaster: Sven F. Crone
Centre for Forecasting
Lancaster University
Management School
Lancaster LA1 4YF
United Kingdom
Tel +44.1524.592991
Fax +44.1524.844885
eMail sven dot crone (at)
neural-forecasting dot com
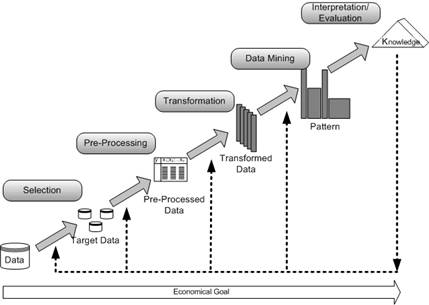
Data mining activities may be distinguished in distinct processes categories. While discovery focuses on searching a database for hidden patterns without a predefined hypothesis about the nature of the pattern and deriving a model of the causal generator of the data, predictive modelling aims to predict future behaviour based upon the model previously discovered in patterns. Forensic Analysis applies the extracted model or patterns to find anomalies in the data. Generally, a model of a structural dependency derived from data may be used for explanation, differentiation of extrapolation into the future. The data mining objective defines the use of a segmentation, association; regression or classification model. Data mining problems in the aCRM domain, such as response optimisation to distinguish between customers who will react to a mailing campaign or not, churn prediction, in the form of classifying customers for churn probability, cross-selling, or up-selling are routinely modelled as classification tasks, predicting a discrete, often binary feature using empirical, customer centred data of past sales, amount of purchases, demographic or psychographic data etc. Conventional statistical methods of logistic regression, discriminant analysis or decision trees are routinely applied to data mining. However, most conventional statistical methods suffer certain drawbacks in real-world scenarios due to their inability to capture nonlinear coherences in addition to requiring a priori assumption for the model building process. Recently, various architectures from computational intelligence and machine learning, such as artificial neural networks (ANN) and support vector machines (SVM) have found increasing consideration in practice, promising effective and efficient solutions for managerial classification problems in real-world applications through robust generalisation in linear and non-linear classification problems, deriving relationships directly from the presented sample data without prior modelling assumptions. Following, we will give a brief discussion on the different classification approaches of the competing soft computing methods